Ever wanted to delete a CSS ruleset, but didn’t know if it was being used on a site? Maybe you want to know how many empty h3s you’ve got. Or maybe you want to know how often a a .title and .subtitle are used together.
I built a thing that can answer that question: The Selector Finder.
Give it a sitemap and a CSS selector, and it’ll scour the site looking for any matches.
Talking Tech and Selecting Selectors
I debated about whether to write this in Python or JavaScript. I’ve done quite a bit of web scraping and automation in Python, so it was my first thought. Except, of course, Python would require me to use the BeautifulSoup library. And BeautifulSoup ain’t pretty to write.
So, Node seemed like a more comfortable choice. Right off the bat, I knew the perfect library: Cheerio. It’s a server-side version of jQuery, so blending that with a basic Ajax library (Axios) would make this pretty straightforward.
I did decide that it would be handy to screengrab the elements, and to at least try to account for SPAs, so I did get Puppeteer involved.
By the time I finished, I was using a grand total of six libraries for this thing. So it’s pretty lightweight by NPM standards.
Setup
This isn’t quite an NPM package, and it isn’t quite a pure CLI; it’s still something in-between. You’ll want to download the code from Github, crack open the command line, go to that directory, and then run npm install to get started.
Usage and Features
The one thing this requires is an XML sitemap. From the command line, you’ll give it the URL to your sitemap, along with a CSS selector
Finding that Selector
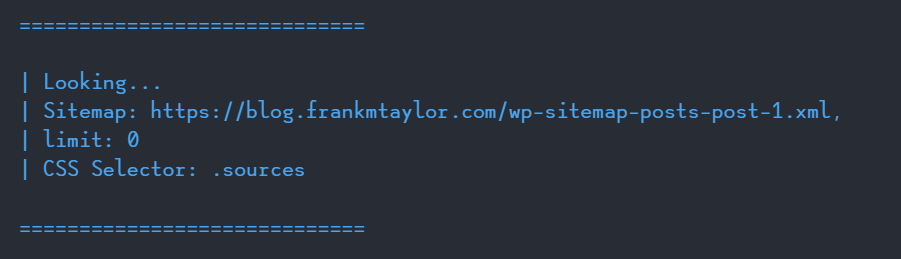
This here will find all the instances of the .sources element on my blog:
node index.js -u "https://blog.frankmtaylor.com/wp-sitemap-posts-post-1.xml" -s ".sources"
I’ll get something like this in the console, to tell me it’s started
And when it finishes, I get a summary of the results
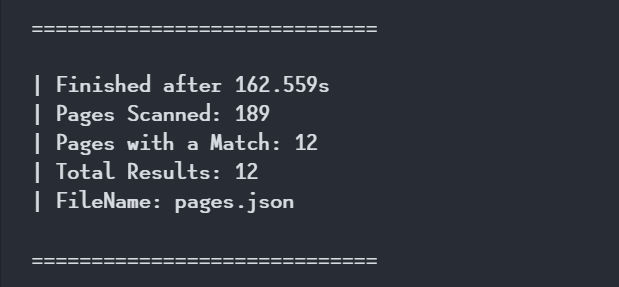
But, where are the results?
Oh, they’re in that pages.json file mentioned in the FileName. They’ll look something like this:
{
"cssSelector": ".sources",
"totalPagesSearched": 189,
"totalMatches": 12,
"pagesWithSelector": [
{
"url": "https://blog.frankmtaylor.com/2013/07/05/css-the-breakdown-part-one-the-selector-and-grammar/",
"totalMatches": 1,
"elements": [
{
"tag": "div",
"attributes": {
"class": "sources"
}
}
]
}
]
}
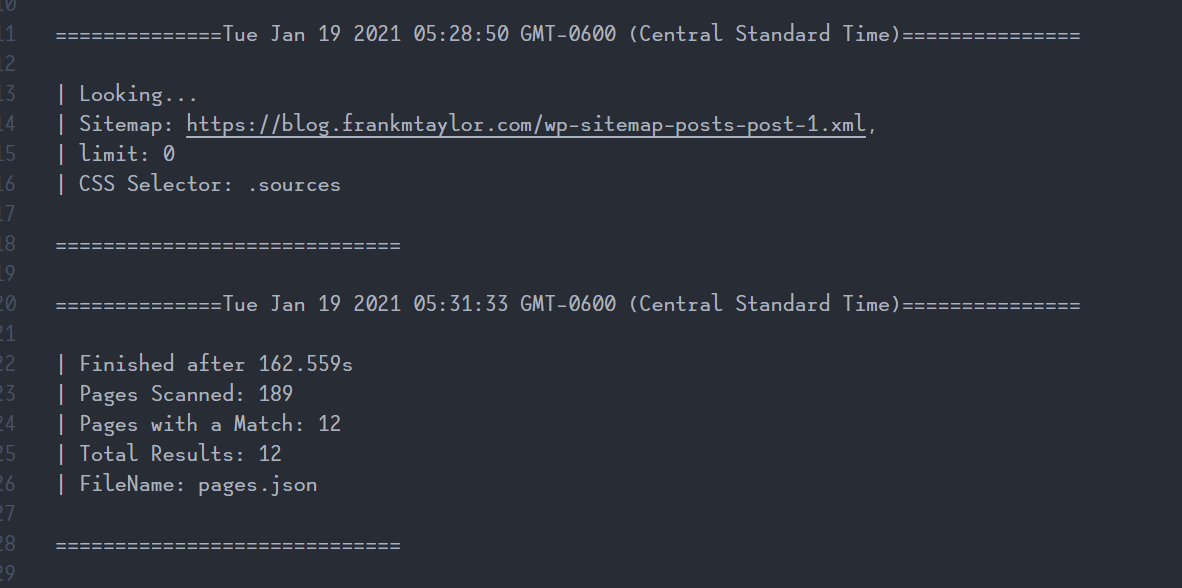
Looking at Logs
This utility writes the logs not just to the console, but to a log file, too. If there’s an issue searching on any page, it’ll pop up in the log.txt file
Additional Options
Limit the number of pages
If it’s a massive sitemap, you can set a limit to how many pages it scans. You can use the --limit or -l parameters to provide a number. If it’s zero, that means there’s no limit.
node index.js -u "https://site/sitemap.xml" -s ".sources" -l 30
Change the output file name (a little)
if you don’t like pages.json as your file name, you can change it to something.pages.json. Use the –outputFileName or -o parameters
node index.js -u "https://site/sitemap.xml" -s ".sources" -o "sourcesclass"
Flag it if it’s a single-page app
By default, this uses Cheerio. But Cheerio isn’t going to find stuff that’s rendered with Vue, Angular, etc on page load. In those cases, we need some rendering. use --isSpa or -d to indicate that this is a single page application. It will take longer to get your results!
node index.js -u "https://site/sitemap.xml" -s ".sources" -d
Take a screenshot
Sometimes it’s not enough to have the tag name and some attributes. Maybe you’d like to see the element. If that’s the case, you can take a screenshot of the element on the page with --takeScreenshots or -c.
node index.js -u "https://site/sitemap.xml" -s ".sources" -c
Wrap-up
This is going to end up being a permanent member of my toolkit, because it does things my IDE can’t. Provided I have a static build, I can search for HTML elements and exact matches. It takes a certain level of RegEx skill not found in the general population to even try fuzzy matches just in a class name.
So the Selector Finder ends up being a really handy way to find out how often some bit of CSS is used, where it’s used, and even get an idea what it looked like before I broke it.
I am considering making it a proper NPM package + CLI utility going forward, but what’s holding me back is the use-case of wanting to scan a local site where you may not have a sitemap, but a directory instead. So stay tuned.